[웹크롤링] beautifulsoup 없이 하드코딩으로 60배 빠르게 웹크롤링하기
2020/11/11 - [python/python 성능개선] - [python] 라인마다 걸리는 시간을 체크해주는 line_profiler
[python] 라인마다 걸리는 시간을 체크해주는 line_profiler
라인 프로파일러를 설치하는 방법은 간단하다. pip install line_profiler 하지만 나는 위 방법으로 자꾸 안깔려서 Anaconda navigator 에서 직접 파일을 검색해서 깔았더니 됬다. (windows) 실행하는 방법은 실
sulung-sulung.tistory.com
이전글에서 beautifulsoup 의 html.parser 가 너무 많은 시간을 잡아 먹는다는것을 알았다.
어떻게 이방식을 알았을까?
html 같은 경우 bytes 파일로 떨어지는데 이걸 먼저 슬라이싱해서 이용을 하면
parser 부분에서 부하가 줄어들지 않을까 생각이 되었다.
html = self.session.get(_url, headers=self.headers).content원래 이부분을
html = self.session.get(_url, headers=self.headers).content[:400000]
이렇게 바꿔주었다.

그냥 html 을 잘려서 번역해줬더니 시간이 줄었다…? 어떤짓을 해도 안줄어들던 시간이 드디어 줄어들었다 ㅠㅠ
그것도 절반이나 ㅠㅠㅠ
한번 더 줄여보겠다!
html = self.session.get(_url, headers=self.headers).content[140000:600000]


헐 뭐야 58.9? 더 쭐어들었잖아.
이제 집요하게 파고들차례다.
어 욕심이 생김. 그럼 저 태그의 인덱스값을 찾으면 최적의 시간을 찾을수 있지 않을까?
index 를 찾는 방법에
len(str.split["태그"][0]) , len(str.split["태그"][-1])
이렇게 찾으면 index값을 바로 찾을수 있을것 같아서 이렇게 해봤다.
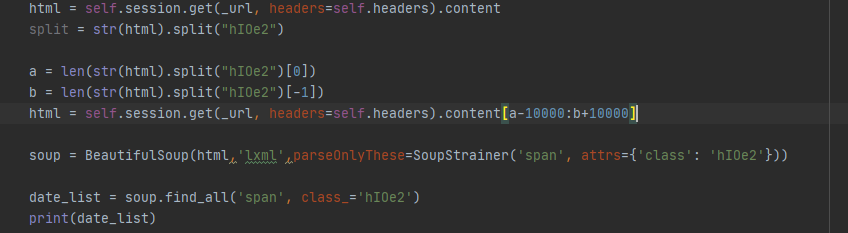

근데 결과는 실패 ㅠㅠㅠㅠ 인덱스 값을 줘도... 근데 인덱스 값을 줘서 저렇게 넣으면 아예 파싱이 안되는 문제도 있어서
앞뒤로 + 10000을 넣어주었다.
그래도 82.6 이나 늘어났다. 왜? 뭐가 문제인걸까??? ㅠㅠㅠ 범위는 더 좁을 텐데

아 이거대로라면 뭔가 index 값 자체의 문제일텐데

결과는 간단했다. str.split["태그"][0] , str.split["태그"][-1] 가 문제였다.
파이썬과 sql을 번갈아 쓰다보면 간단한 식도 까먹는다.
str.index("태그") , str.rindex("태그") 를 하면 엄청 빨라진다.
하지만 여기서 str로 굳이 바꿀 필요없이 byte.index(b'태그') 하면 빠르게 index값을 받을 수 있는것을 알았다.
str(byte).index('태그') ====> byte.index(b'태그')
html = self.session.get(_url, headers=self.headers).content
html = html[html.index(b'<span class="hIOe2">'):html.rindex(b'<span class="hIOe2">')]
자 이렇게 하면 빨라진다.

hit Time 이 기존 82 -> 68 이 되었다.
하지만 여기서 나는 parser를 직접 정규식을 이용해서 코드를 다시 짜봤다.
import re
#soup = BeautifulSoup(html,'lxml',parseOnlyThese=SoupStrainer('span', attrs={'class': 'hIOe2'}))
#date_list = soup.find_all('span', class_='hIOe2') 을 대신하는 코드
soup = html.decode()
date_list = re.compile('[\u3131-\u3163\uac00-\ud7a3]+').findall(soup)
한글 코드 범위
ㄱ ~ ㅎ: 0x3131 ~ 0x314e
ㅏ ~ ㅣ: 0x314f ~ 0x3163
가 ~ 힣: 0xac00 ~ 0xd7a3
re.compile('[^ ㄱ-ㅣ가-힣]+') = re.compile('[\u3131-\u3163\uac00-\ud7a3]+')
이다. 이렇게 하면 모든 한글 단어만 파싱할수 있다.

그랬더니 hit Time 이 68 -> 1.2 이 되었다.
결과도 너무 잘됬다.
이제 뷰티풀숲은 쓰레기통에 넣어야겠다. 이정도로 메모리와 시간을 잡아먹는다고? line_profiler 가 아니었으면 몰랐다.
제목은 좀 어그로지만 그럴 가치가 있는것 같다. 웹크롤링 자체 시간은 트래픽도 고려해서 짜야하므로
전체적으로는 4~5배는 줄어든것 같다. 병렬처리 스레드처리 했을때 보다 거어어어어업나 빠르다.