반응형
데이터 셋 : Imdb
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 첫 번째 GPU만 사용하도록 제한
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
except RuntimeError as e:
print(e)
MAX_SENTENCES = 10
MAX_SENTENCE_LENGTH = 25import os, re
import pandas as pd
import tensorflow as tf
from tensorflow.keras import utils
dataset = tf.keras.utils.get_file( fname='imdb.tar.gz', # 다운받은 압축파일의 이름
origin = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz", # 링크주소
extract = True)
basic_dir = os.path.dirname(dataset)
print(basic_dir)
os.path.join(basic_dir, 'aclImdb') # os.path.join(basic_dir, 'aclImdb') 이라고 입력하시면, 그 데이터셋보다 한 단계 아래인 폴더에까지 접근이 가능합니다. 이렇게 os.path.join 함수는 디렉터리 경로를 조인해주는 역할을 합니다.
path_train_pos = os.path.join(basic_dir, 'aclImdb', 'train', 'pos')
path_train_pos
#'C:\\Users\\user\\.keras\\datasets\\aclImdb\\train\\pos'
# refer: http://ai.stanford.edu/~amaas/data/sentiment/
import os
data_dir = os.path.join(basic_dir, 'aclImdb')
train_dir = os.path.join(data_dir, 'train')
test_dir = os.path.join(data_dir, 'test')
def load_dataset(split='train'):
x_data = []
y_data = []
base_dir = os.path.join(basic_dir, 'aclImdb')
split_dir = os.path.join(base_dir, split)
for sentiment, y in [('neg', 0), ('pos', 1)]:
data_dir = os.path.join(split_dir, sentiment)
for file_name in os.listdir(data_dir):
file_path = os.path.join(data_dir, file_name)
with open(file_path, 'r', encoding='utf-8') as fp:
review = fp.read()
x_data.append(review)
y_data.append(y)
return x_data, y_data
train_x_data, train_y_data = load_dataset(split='train')
test_x_data, test_y_data = load_dataset(split='test')
print("len(train_x_data): {}".format(len(train_x_data)))
print("len(test_x_data): {}".format(len(test_x_data)))
len(train_x_data): 25000
len(test_x_data): 25000
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
def average(x):
return sum(x) / len(x)
avg_nb_words = average([len(review.strip().split()) for review in train_x_data])
print("Average # of words: {}".format(avg_nb_words))
# Average # of words: 233.7872
avg_nb_sentences = average([len(sent_tokenize(review)) for review in train_x_data])
print("Average # of sentences: {}".format(avg_nb_sentences))
# Average # of sentences: 10.83412
avg_nb_words_in_sentence = average([average([len(sent.strip().split()) for sent in sent_tokenize(review)]) for review in train_x_data])
print("Average # of words in sentence: {}".format(avg_nb_words_in_sentence))
# Average # of words in sentence: 24.953852357350815
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from nltk.tokenize import sent_tokenize
tokenizer = Tokenizer()
tokenizer.fit_on_texts(train_x_data)
tokenizer.fit_on_texts(test_x_data)
max_nb_words = len(tokenizer.word_index) + 1
def doc2hierarchical(text,
max_sentences=MAX_SENTENCES,
max_sentence_length=MAX_SENTENCE_LENGTH):
sentences = sent_tokenize(text)
tokenized_sentences = tokenizer.texts_to_sequences(sentences)
tokenized_sentences = pad_sequences(tokenized_sentences, maxlen=max_sentence_length)
pad_size = max_sentences - tokenized_sentences.shape[0]
if pad_size <= 0: # tokenized_sentences.shape[0] < max_sentences
tokenized_sentences = tokenized_sentences[:max_sentences]
else:
tokenized_sentences = np.pad(
tokenized_sentences, ((0, pad_size), (0, 0)),
mode='constant', constant_values=0
)
return tokenized_sentences
def build_dataset(x_data, y_data,
max_sentences=MAX_SENTENCES,
max_sentence_length=MAX_SENTENCE_LENGTH,
tokenizer=tokenizer):
nb_instances = len(x_data)
X_data = np.zeros((nb_instances, max_sentences, max_sentence_length), dtype='int32')
for i, review in enumerate(x_data):
tokenized_sentences = doc2hierarchical(review)
X_data[i] = tokenized_sentences[None, ...]
nb_classes = len(set(y_data))
Y_data = to_categorical(y_data, nb_classes)
return X_data, Y_data
train_X_data, train_Y_data = build_dataset(train_x_data, train_y_data)
test_X_data, test_Y_data = build_dataset(test_x_data, test_y_data)
print("train_X_data.shape: {}".format(train_X_data.shape))
print("test_X_data.shape: {}".format(test_X_data.shape))train_X_data.shape: (25000, 10, 25)
test_X_data.shape: (25000, 10, 25)
from sklearn.model_selection import train_test_split
train_X_data, val_X_data, train_Y_data, val_Y_data = train_test_split(train_X_data, train_Y_data,
test_size=0.1,
random_state=42)
print("train_X_data.shape: {}".format(train_X_data.shape))
print("train_Y_data.shape: {}".format(train_Y_data.shape))
print("val_X_data.shape: {}".format(val_X_data.shape))
print("val_Y_data.shape: {}".format(val_Y_data.shape))
train_X_data.shape: (22500, 10, 25)
train_Y_data.shape: (22500, 2)
val_X_data.shape: (2500, 10, 25)
val_Y_data.shape: (2500, 2)
embedding_dir = './embeddings/'
def load_word2vec(tokenizer=tokenizer):
from gensim.models import KeyedVectors
embedding_path = os.path.join(embedding_dir, 'GoogleNews-vectors-negative300.bin')
embeddings_index = KeyedVectors.load_word2vec_format(embedding_path, binary=True)
return embeddings_index
def load_embedding(embedding_type='word2vec',
tokenizer=tokenizer,
embedding_dim=300):
if embedding_type == 'word2vec':
embeddings_index = load_word2vec()
embedding_matrix = np.random.normal(0, 1, (max_nb_words, embedding_dim))
for word, i in tokenizer.word_index.items():
try:
embedding_vector = embeddings_index[word]
except KeyError:
embedding_vector = None
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
return embedding_matrix
embedding_matrix = load_embedding('word2vec')
print("embedding_matrix.shape: {}".format(embedding_matrix.shape))embedding_matrix.shape: (124253, 300)
import tensorflow.keras as keras
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.layers import Layer, InputSpec
from tensorflow.python.keras.layers import Input, Embedding, Dense
from tensorflow.python.keras.layers import Lambda, Permute, RepeatVector, Multiply
from tensorflow.python.keras.layers import Bidirectional, TimeDistributed
from tensorflow.python.keras.layers import GRU
from tensorflow.python.keras.layers import BatchNormalization, Dropout
from tensorflow.python.keras.models import Model, Sequential
from tensorflow.python.keras.callbacks import ModelCheckpoint
class AttentionLayer(Layer):
def __init__(self, attention_dim, **kwargs):
self.attention_dim = attention_dim
super(AttentionLayer, self).__init__(**kwargs)
def build(self, input_shape):
self.W = self.add_weight(name='Attention_Weight',
shape=(input_shape[-1], self.attention_dim),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(name='Attention_Bias',
shape=(self.attention_dim, ),
initializer='random_normal',
trainable=True)
self.u = self.add_weight(name='Attention_Context_Vector',
shape=(self.attention_dim, 1),
initializer='random_normal',
trainable=True)
super(AttentionLayer, self).build(input_shape)
def call(self, x):
# refer to the original paper
# link: https://www.cs.cmu.edu/~hovy/papers/16HLT-hierarchical-attention-networks.pdf
u_it = K.tanh(K.dot(x, self.W) + self.b)
a_it = K.dot(u_it, self.u)
a_it = K.squeeze(a_it, -1)
a_it = K.softmax(a_it)
return a_it
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1])
def WeightedSum(attentions, representations):
# from Shape(batch_size, len_units) to Shape(batch_size, rnn_dim * 2, len_units)
repeated_attentions = RepeatVector(K.int_shape(representations)[-1])(attentions)
# from Shape(batch_size, rnn_dim * 2, len_units) to Shape(batch_size, len_units, lstm_dim * 2)
repeated_attentions = Permute([2, 1])(repeated_attentions)
# compute representation as the weighted sum of representations
aggregated_representation = Multiply()([representations, repeated_attentions])
aggregated_representation = Lambda(lambda x: K.sum(x, axis=1))(aggregated_representation)
return aggregated_representation
def HieAtt(embedding_matrix,
max_sentences,
max_sentence_length,
nb_classes,
embedding_dim=300,
attention_dim=100,
rnn_dim=150,
include_dense_batch_normalization=False,
include_dense_dropout=True,
nb_dense=1,
dense_dim=300,
dense_dropout=0.2,
optimizer = keras.optimizers.Adam(lr=0.001)):
# embedding_matrix = (max_nb_words + 1, embedding_dim)
max_nb_words = embedding_matrix.shape[0] - 1
embedding_layer = Embedding(max_nb_words + 1,
embedding_dim,
weights=[embedding_matrix],
input_length=max_sentence_length,
trainable=False)
# first, build a sentence encoder
sentence_input = Input(shape=(max_sentence_length, ), dtype='int32')
embedded_sentence = embedding_layer(sentence_input)
embedded_sentence = Dropout(dense_dropout)(embedded_sentence)
contextualized_sentence = Bidirectional(GRU(rnn_dim, return_sequences=True))(embedded_sentence)
# word attention computation
word_attention = AttentionLayer(attention_dim)(contextualized_sentence)
sentence_representation = WeightedSum(word_attention, contextualized_sentence)
sentence_encoder = Model(inputs=[sentence_input],
outputs=[sentence_representation])
# then, build a document encoder
document_input = Input(shape=(max_sentences, max_sentence_length), dtype='int32')
embedded_document = TimeDistributed(sentence_encoder)(document_input)
contextualized_document = Bidirectional(GRU(rnn_dim, return_sequences=True))(embedded_document)
# sentence attention computation
sentence_attention = AttentionLayer(attention_dim)(contextualized_document)
document_representation = WeightedSum(sentence_attention, contextualized_document)
# finally, add fc layers for classification
fc_layers = Sequential()
for _ in range(nb_dense):
if include_dense_batch_normalization == True:
fc_layers.add(BatchNormalization())
fc_layers.add(Dense(dense_dim, activation='relu'))
if include_dense_dropout == True:
fc_layers.add(Dropout(dense_dropout))
fc_layers.add(Dense(nb_classes, activation='softmax'))
pred_sentiment = fc_layers(document_representation)
model = Model(inputs=[document_input],
outputs=[pred_sentiment])
############### build attention extractor ###############
word_attention_extractor = Model(inputs=[sentence_input],
outputs=[word_attention])
word_attentions = TimeDistributed(word_attention_extractor)(document_input)
attention_extractor = Model(inputs=[document_input],
outputs=[word_attentions, sentence_attention])
model.compile(loss=['categorical_crossentropy'],
optimizer=optimizer,
metrics=['accuracy'])
return model, attention_extractor
model_name = "HieAtt"
model_path = './models/checkpoints/{}.h5'.format(model_name)
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath=model_path,monitor='val_acc',verbose=True,save_best_only=True,mode='max')
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
model, attention_extractor = HieAtt(embedding_matrix=embedding_matrix,
max_sentences=MAX_SENTENCES,
max_sentence_length=MAX_SENTENCE_LENGTH,
nb_classes=2,
embedding_dim=300,
attention_dim=100,
rnn_dim=150,
include_dense_batch_normalization=False,
include_dense_dropout=True,
nb_dense=1,
dense_dim=300,
dense_dropout=0.2,
optimizer = keras.optimizers.Adam(lr=0.001))
history = model.fit(x=train_X_data,
y=train_Y_data,
batch_size=128,
epochs=30,
verbose=True,
validation_data=(val_X_data, val_Y_data),
callbacks=[checkpointer,callback]
)
val_X_data.shape
# (2500, 10, 25)
score = model.evaluate(test_X_data, test_Y_data, verbose=0, batch_size=128)
print("Test Accuracy of {}: {}".format(model_name, score[1]))
#Test Accuracy of HieAtt: 0.
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()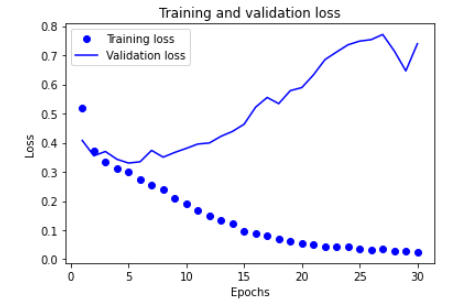
plt.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()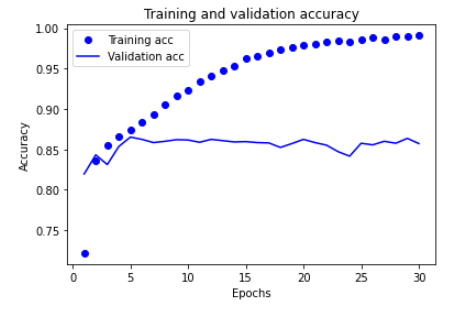
model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 10, 25)] 0
__________________________________________________________________________________________________
time_distributed (TimeDistribut (None, 10, 300) 37712000 input_2[0][0]
__________________________________________________________________________________________________
bidirectional_1 (Bidirectional) (None, 10, 300) 405900 time_distributed[0][0]
__________________________________________________________________________________________________
attention_layer_1 (AttentionLay (None, 10) 30200 bidirectional_1[0][0]
__________________________________________________________________________________________________
repeat_vector_1 (RepeatVector) (None, 300, 10) 0 attention_layer_1[0][0]
__________________________________________________________________________________________________
permute_1 (Permute) (None, 10, 300) 0 repeat_vector_1[0][0]
__________________________________________________________________________________________________
multiply_1 (Multiply) (None, 10, 300) 0 bidirectional_1[0][0]
permute_1[0][0]
__________________________________________________________________________________________________
lambda_1 (Lambda) (None, 300) 0 multiply_1[0][0]
__________________________________________________________________________________________________
sequential (Sequential) (None, 2) 90902 lambda_1[0][0]
==================================================================================================
Total params: 38,239,002
Trainable params: 963,102
Non-trainable params: 37,275,900
import seaborn as sn
word_rev_index = {}
for word, i in tokenizer.word_index.items():
word_rev_index[i] = word
def sentiment_analysis(review):
tokenized_sentences = doc2hierarchical(review)
# word attention만 가져오기
pred_attention = attention_extractor.predict(np.asarray([tokenized_sentences]))[0][0]
for sent_idx, sentence in enumerate(tokenized_sentences):
if sentence[-1] == 0:
continue
for word_idx in range(MAX_SENTENCE_LENGTH):
if sentence[word_idx] != 0:
words = [word_rev_index[word_id] for word_id in sentence[word_idx:]]
pred_att = pred_attention[sent_idx][-len(words):]
pred_att = np.expand_dims(pred_att, axis=0)
break
fig, ax = plt.subplots(figsize=(len(words), 1))
plt.rc('xtick', labelsize=16)
midpoint = (max(pred_att[:, 0]) - min(pred_att[:, 0])) / 2
heatmap = sn.heatmap(pred_att, xticklabels=words, yticklabels=False, square=True, linewidths=0.1, cmap='coolwarm', center=midpoint, vmin=0, vmax=1)
plt.xticks(rotation=45)
plt.show()
# sentiment_analysis("Delicious healthy food. The steak is amazing. Fish and pork are awesome too. Service is above and beyond. Not a bad thing to say about this place. Worth every penny!")
sentiment_analysis("i want to go home")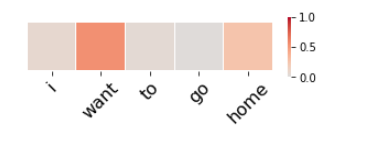
이 블로그를 참고했다! 케라스 버전 에러를 다 수정해서 고쳐봤다.
Hierarchical Attention Networks for Document Classification 이 논문은 조만간 또 리뷰할 예정..
반응형
'딥러닝 > 자연어처리' 카테고리의 다른 글
| 코사인 유사도 (Cosine Similarity) (0) | 2020.12.01 |
|---|---|
| [word2vec] 카카오 댓글데이터로 word2vec 임베딩 해보기 (0) | 2020.11.10 |
| 자연어 처리 보면 좋을 자료 모음 (0) | 2020.11.10 |


댓글